Publications
* denotes equal contribution and joint lead authorship.
2024
-
 "Previously on ..." From Recaps to Story SummarizationAditya Singh, Dhruv Srivastava, and Makarand TapaswiIn IEEE Conference on Computer Vision and Pattern Recognition,, 2024
"Previously on ..." From Recaps to Story SummarizationAditya Singh, Dhruv Srivastava, and Makarand TapaswiIn IEEE Conference on Computer Vision and Pattern Recognition,, 2024We introduce multimodal story summarization by leveraging TV episode recaps – short video sequences interweaving key story moments from previous episodes to bring viewers up to speed. We propose PlotSnap, a dataset featuring two crime thriller TV shows with rich recaps and long episodes of 40 minutes. Story summarization labels are unlocked by matching recap shots to corresponding substories in the episode. We propose a hierarchical model TaleSumm that processes entire episodes by creating compact shot and dialog representations, and predicts importance scores for each video shot and dialog utterance by enabling interactions between local story groups. Unlike traditional summarization, our method extracts multiple plot points from long videos. We present a thorough evaluation on story summarization, including promising cross-series generalization. TaleSumm also shows good results on classic video summarization benchmarks.
@inproceedings{singh2024previously, title = {"Previously on ..." From Recaps to Story Summarization}, author = {Singh, Aditya and Srivastava, Dhruv and Tapaswi, Makarand}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition,}, year = {2024}, } -
 FolkTalent: Enhancing Classification and Tagging of Indian Folk PaintingsNancy Hada, Aditya Singh, and Kavita Vemuri2024
FolkTalent: Enhancing Classification and Tagging of Indian Folk PaintingsNancy Hada, Aditya Singh, and Kavita Vemuri2024Indian folk paintings have a rich mosaic of symbols, colors, textures, and stories making them an invaluable repository of cultural legacy. The paper presents a novel approach to classifying these paintings into distinct art forms and tagging them with their unique salient features. A custom dataset named FolkTalent, comprising 2279 digital images of paintings across 12 different forms, has been prepared using websites that are direct outlets of Indian folk paintings. Tags covering a wide range of attributes like color, theme, artistic style, and patterns are generated using GPT4, and verified by an expert for each painting. Classification is performed employing the RandomForest ensemble technique on fine-tuned Convolutional Neural Network (CNN) models to classify Indian folk paintings, achieving an accuracy of 91.83%. Tagging is accomplished via the prominent fine-tuned CNN-based backbones with a custom classifier attached to its top to perform multi-label image classification. The generated tags offer a deeper insight into the painting, enabling an enhanced search experience based on theme and visual attributes. The proposed hybrid model sets a new benchmark in folk painting classification and tagging, significantly contributing to cataloging India’s folk-art heritage.
@article{hada2024folktalentenhancingclassificationtagging, title = {FolkTalent: Enhancing Classification and Tagging of Indian Folk Paintings}, author = {Hada, Nancy and Singh, Aditya and Vemuri, Kavita}, booktitle = {International Conference on FOSS Approaches towards Computational Intelligence and Language Technology,}, year = {2024}, } -
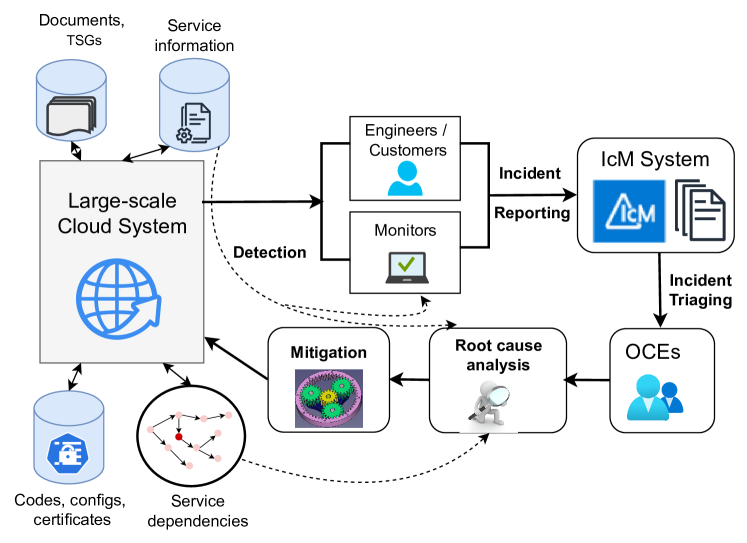 X-lifecycle Learning for Cloud Incident Management using LLMsIn ACM International Conference on the Foundations of Software Engineering,, 2024
X-lifecycle Learning for Cloud Incident Management using LLMsIn ACM International Conference on the Foundations of Software Engineering,, 2024Incident management for large cloud services is a complex and tedious process and requires significant amount of manual efforts from on-call engineers (OCEs). OCEs typically leverage data from different stages of the software development lifecycle [SDLC] (e.g., codes, configuration, monitor data, service properties, service dependencies, trouble-shooting documents, etc.) to generate insights for detection, root causing and mitigating of incidents. Recent advancements in large language models [LLMs] (e.g., ChatGPT, GPT-4, Gemini) created opportunities to automatically generate contextual recommendations to the OCEs assisting them to quickly identify and mitigate critical issues. However, existing research typically takes a silo-ed view for solving a certain task in incident management by leveraging data from a single stage of SDLC. In this paper, we demonstrate that augmenting additional contextual data from different stages of SDLC improves the performance of two critically important and practically challenging tasks: (1) automatically generating root cause recommendations for dependency failure related incidents, and (2) identifying ontology of service monitors used for automatically detecting incidents. By leveraging 353 incident and 260 monitor dataset from Microsoft, we demonstrate that augmenting contextual information from different stages of the SDLC improves the performance over State-of-The-Art methods.
@inproceedings{goel2024xlifecyclelearningcloudincident, title = {X-lifecycle Learning for Cloud Incident Management using LLMs}, author = {Goel, Drishti and Husain, Fiza and Singh, Aditya and Ghosh, Supriyo and Parayil, Anjaly and Bansal, Chetan and Zhang, Xuchao and Rajmohan, Saravan}, booktitle = {ACM International Conference on the Foundations of Software Engineering,}, year = {2024}, }


2023
-
 How you feelin’? Learning Emotions and Mental States in Movie ScenesDhruv Srivastava, Aditya Singh, and Makarand TapaswiIn IEEE Conference on Computer Vision and Pattern Recognition,, 2023
How you feelin’? Learning Emotions and Mental States in Movie ScenesDhruv Srivastava, Aditya Singh, and Makarand TapaswiIn IEEE Conference on Computer Vision and Pattern Recognition,, 2023Movie story analysis requires understanding characters’ emotions and mental states. Towards this goal, we formulate emotion understanding as predicting a diverse and multi-label set of emotions at the level of a movie scene and for each character. We propose EmoTx, a multimodal Transformer-based architecture that ingests videos, multiple characters, and dialog utterances to make joint predictions. By leveraging annotations from the MovieGraphs dataset, we aim to predict classic emotions (e.g. happy, angry) and other mental states (e.g. honest, helpful). We conduct experiments on the most frequently occurring 10 and 25 labels, and a mapping that clusters 181 labels to 26. Ablation studies and comparison against adapted state-of-the-art emotion recognition approaches shows the effectiveness of EmoTx. Analyzing EmoTx’s self-attention scores reveals that expressive emotions often look at character tokens while other mental states rely on video and dialog cues.
@inproceedings{dhruv2023emotx, title = {How you feelin'? Learning Emotions and Mental States in Movie Scenes}, author = {Srivastava, Dhruv and Singh, Aditya and Tapaswi, Makarand}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition,}, year = {2023}, }

2022
- arXivMulti-Label Classification on Remote-Sensing ImagesAditya Singh, and B Uma ShankararXiv preprint arXiv:2201.01971, 2022
Acquiring information on large areas on the earth’s surface through satellite cameras allows us to see much more than we can see while standing on the ground. This assists us in detecting and monitoring the physical characteristics of an area like land-use patterns, atmospheric conditions, forest cover, and many unlisted aspects. The obtained images not only keep track of continuous natural phenomena but are also crucial in tackling the global challenge of severe deforestation. Among which Amazon basin accounts for the largest share every year. Proper data analysis would help limit detrimental effects on the ecosystem and biodiversity with a sustainable healthy atmosphere. This report aims to label the satellite image chips of the Amazon rainforest with atmospheric and various classes of land cover or land use through different machine learning and superior deep learning models. Evaluation is done based on the F2 metric, while for loss function, we have both sigmoid cross-entropy as well as softmax cross-entropy. Images are fed indirectly to the machine learning classifiers after only features are extracted using pre-trained ImageNet architectures. Whereas for deep learning models, ensembles of fine-tuned ImageNet pre-trained models are used via transfer learning. Our best score was achieved so far with the F2 metric is 0.927.
@article{singh2022multi, title = {Multi-Label Classification on Remote-Sensing Images}, author = {Singh, Aditya and Shankar, B Uma}, journal = {arXiv preprint arXiv:2201.01971}, year = {2022}, volume = {abs/2201.01971}, url = {https://arxiv.org/abs/2201.01971}, timestamp = {Mon, 10 Jan 2022 13:39:01 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2201-01971.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, publisher = {arXiv} }